Что такое LUN (лун)?

Что такое LUN (лун)?
Сообщение gs » 13 июл 2007, 15:10
Сначала немного теории.
LUN = Logical Unit Number
В сказевых системах (а также FC, SAS и практически всех рэйд контроллерах, даже саташных) используется следующая схема адресации устройств — шина (Bus) — адрес (ID) — подадрес (LUN). Аналогия простая: улица — дом — квартира.
Понятие лунов введено в скази стандарт, т.к. существует много систем, где на одном адресе сидит много разных устройств. Например внешние дисковые системы, которые цепляются к серверу одним кабелем — один порт имеет один адрес. Вот чтобы на этом одном адресе видеть кучу дисков, и нужны луны.
Луном может быть не только логический диск. Это может быть например мониторинговый SES процессор или сам контроллер (для управления непосредственно через шину, без эзернетовского хвоста).
Теперь ближе к обыденности.
В просторечии лунами обычно называют логические диски — что не совсем корректно, но общепринято.
Внутри рэйд системы существуют массивы (array) и логические диски (logical drive). Логический диск фактически является партицией массива — только не на уровне операционки, а внутри контроллера.
Грубо говоря, LUN (Logical Drive), с представляет собой кусок рэйд массива, который контроллер представляет операционной системе в качестве «физического» диска. Именно это как правило и имеется в виду, когда говорят «лун».
Смысл разбиения массива на луны в том, что на разных лунах можно иметь разные политики кэширования, что невозможно в случае обычных софтовых партиций. А на многих контроллерах еще и разные уровни рэйд (например контроллеры Адаптек или LSI). Еще момент — не всегда операционки понимают диски более 2ТБ (хотя это со временем пройдет) — тогда большой массив можно просто порезать.
Обладатели PCI контроллеров могут дальше не читать
Сами по себе логдрайвы никому не видны. Для того, чтобы их увидела система, им надо присвоить номера — LUNы.
В PCI контроллерах это делается автоматом, т.к. вариантов нет (т.е. LUN=LogDrive).
Во внешних дисковых системах все гораздо сложнее. Например может существовать логический драйв, не имеющий собственного луна вообще — например разного рода теневые копии. Или наоборот, в случае инкрементального снапшота один и тот же драйв может быть опубликован под разными номерами — как снимки на разный момент времени.
Еще момент — storage partitioning. Это означает виртуальное деление дисковой системы на несколько (для удобства подключения большого количества серверов). В этом случае с разных хостов под одними и теми же номерами лунов будут видны разные логдрайвы.
LUN Mapping — маскирование лунов для разных серверов. Это для того, чтобы разные сервера не видели луны соседа и не мешали друг другу. Можно сказать упрощенный вариант сторадж партишенинга.
В общем, во внешних системах логические диски и луны — это не одно и то же. И задание номеров лунов есть задача админа.
Источник
Нарезать LUN (по 850Gb) для каждого ESXi сервера и сделать привязку только конкретного.
«LUN» или «Logical Unit Number« — это адрес диска или дискового устройства в сетях хранения.
«Storage Management Utility P2000 G3 FC» – моё хранилище.
1,2,3,6 – у меня стоят диск по 3Tb (6G DP 7.2K (SAS MOL))
Хранилище подключено к «Qlogic SandBox 5800» из него по оптике в каждый «ESXi» сервер.
Подключаем на консоль «Storage Management Utility»
посредством браузера на адрес настроенного хранилища. Вводим административный логин и пароль.
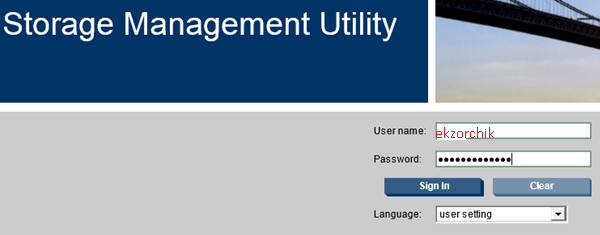
Раскрыв хранилище в элементе «Hosts» представлены обнаруженные «ESXi» подключенные к моему «Storage P2000 G3 FC» по оптике, вообще при подключении они именуют, как «HOST ID», этот хост «ID» у каждого сервера возле коннектора написан на приклеенной бумажке. Для своего удобства я данные «ESXi» просто переименовал в удобные мне имена.
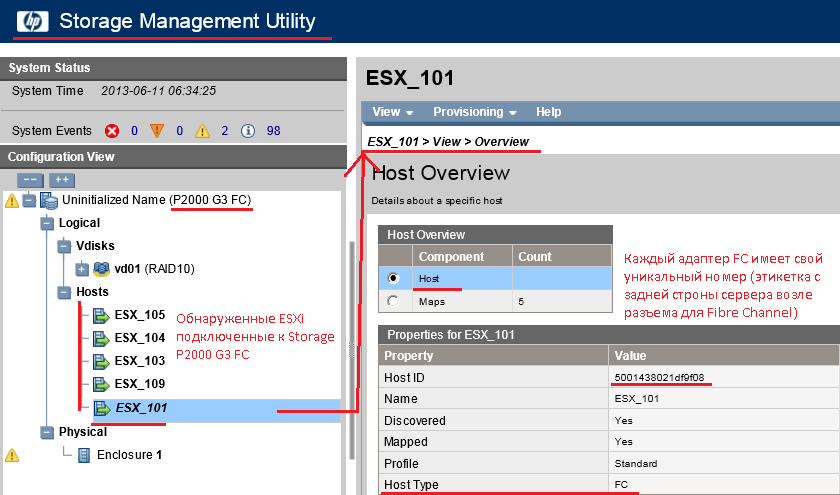
И так у меня есть «12Tb» – мне надо сделать «RAID 10».
Чтобы создать «LUN» нужно сперва создать логический диск (предварительно сделав RAID, в моем, случаем это будет RAID 10)
Правой кнопкой вызываем меню свойств – «Provisioning» – «Create Vdisk».
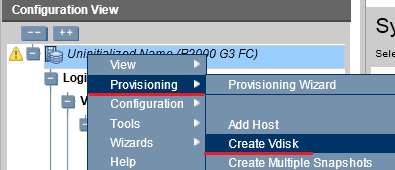
Именуем его vd 01:
Тип создаваемого «RAID’а» – «RAID 10».
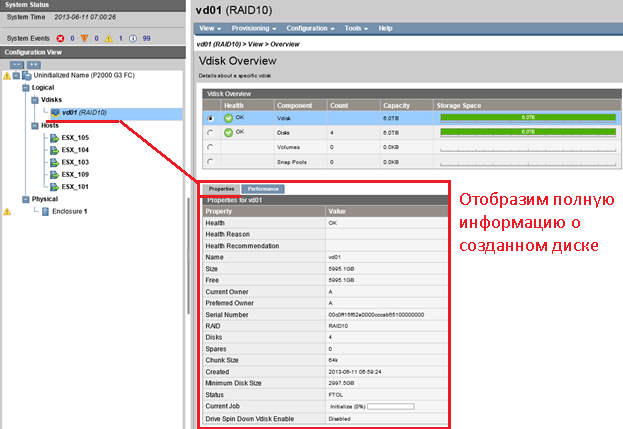
Посмотрим полную техническую информацию :
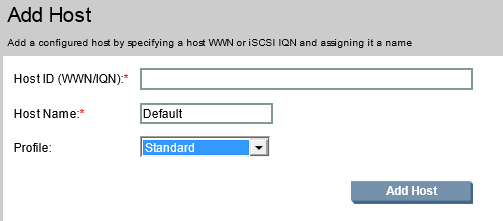
Создаем «Add Host» – если «ESXi» сервера не определились, потребуется идентификатор адаптера сетевой карточки.
При создании Host’а нужно будет ввести его уникальный ID сетевой карточки.
, но в моем случаем хост автоматически зарегистрировался на хранилище в виде цифрового кода , вида:
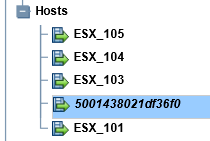
Данную последовательность цифр удобнее переименовать, чтобы оперировать, более смысловыми обозначениями, для меня удобнее обозначать видом: «ESX_109» (, где 109) – это последний октет IP-адреса.
Теперь переходим к созданию LUN на моем RAID’ е размером 850Gb:
Раскрываем созданный vd01 (RAID 10) – и создаем «LUN» – «Provisioninig» – «Create Volume».
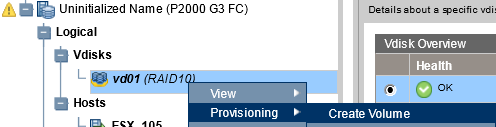
Именуем создаваемый «LUN», устанавливаем размер «850 Gb» и обязательно не устанавливаем галочку у пункта «Map» – после того как все сделано нажимаем «Apply».
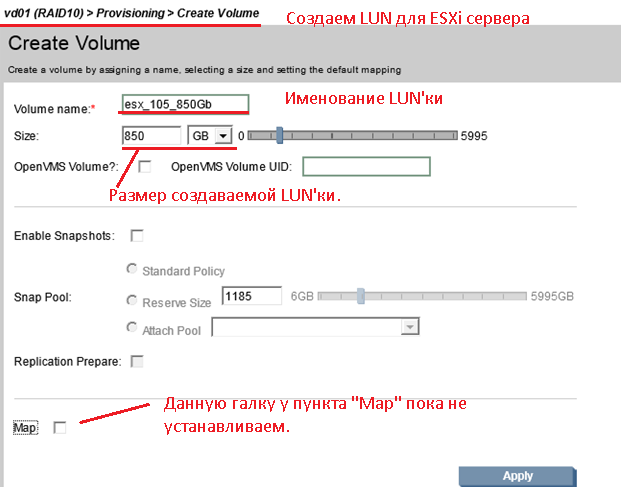
Теперь свяжем созданную «LUN’ку» (именуемую, как esx_105_850Gb) с хостом «ESX_105» c правами «READ and Write».
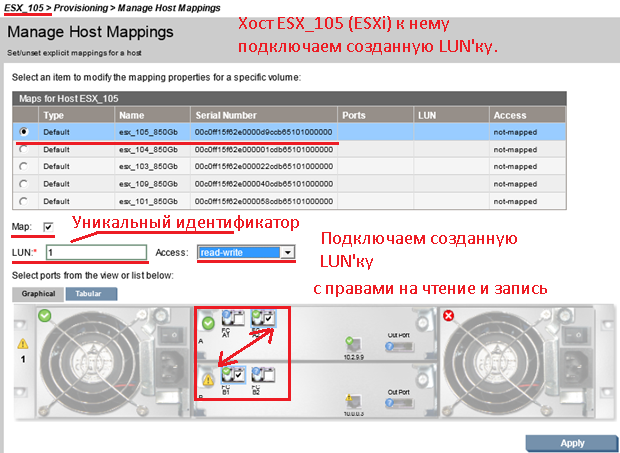
«ESX_105» – «Provisioning» – «Manage Host Mappings».

Указываем, что примапить галочку у пункта «Map» и указываем индивидуальный номер «LUN» под которым данный кусок будет видится на «ESXi».
В итоге перейдя на элемент «Hosts» – «ESX_105» – «Maps» – видно, что к данному хосту примаплен а «LUN’ка» к «esx_105_850Gb» с номером «1» и правами чтения и записи .
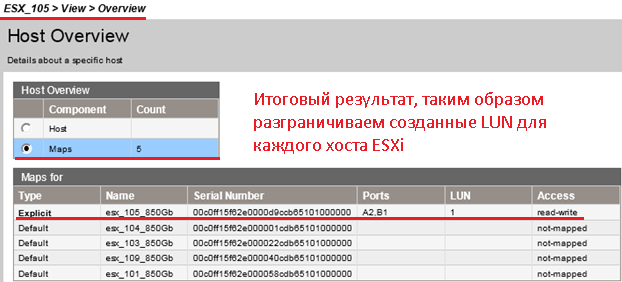
Вот собственно и всё что требовалось и полной мере рассмотрено. С уважением, ekzorchik.
Источник
О сетях хранения данных
Решил написать небольшую статейку о сетях хранения данных (СХД), тема эта достаточно интересная, но на Хабре почему-то не раскрыта. Постараюсь поделиться личным опытом по построению и поддержке SAN.
Что это?
Сеть хранения данных, или Storage Area Network — это система, состоящая из собственно устройств хранения данных — дисковых, или RAID — массивов, ленточных библиотек и прочего, среды передачи данных и подключенных к ней серверов. Обычно используется достаточно крупными компаниями, имеющими развитую IT инфраструктуру, для надежного хранения данных и скоростного доступа к ним.
Упрощенно, СХД — это система, позволяющая раздавать серверам надежные быстрые диски изменяемой емкости с разных устройств хранения данных.
Немного теории.
Сервер к хранилищу данных можно подключить несколькими способами.
Первый и самый простой — DAS, Direct Attached Storage (прямое подключение), без затей ставим диски в сервер, или массив в адаптер сервера — и получаем много гигабайт дискового пространства со сравнительно быстрым доступом, и при использовании RAID-массива — достаточную надежность, хотя копья на тему надежности ломают уже давно.
Однако такое использование дискового пространства не оптимально — на одном сервере место кончается, на другом его еще много. Решение этой проблемы — NAS, Network Attached Storage (хранилище, подключенное по сети). Однако при всех преимуществах этого решения — гибкости и централизованного управления — есть один существенный недостаток — скорость доступа, еще не во всех организациях внедрена сеть 10 гигабит. И мы подходим к сети хранения данных.
Главное отличие SAN от NAS (помимо порядка букв в аббревиатурах) — это то, каким образом видятся подключаемые ресурсы на сервере. Если в NAS ресурсы подключаются протоколам NFS или SMB, в SAN мы получаем подключение к диску, с которым можем работать на уровне операций блочного ввода-вывода, что гораздо быстрее сетевого подключения (плюс контроллер массива с большим кэшем добавляет скорости на многих операциях).
Используя SAN, мы сочетаем преимущества DAS — скорость и простоту, и NAS — гибкость и управляемость. Плюс получаем возможность масштабирования систем хранения до тех пор, пока хватает денег, параллельно убивая одним выстрелом еще несколько зайцев, которых сразу не видно:
* снимаем ограничения на дальность подключения SCSI-устройств, которые обычно ограничены проводом в 12 метров,
* уменьшаем время резервного копирования,
* можем грузиться с SAN,
* в случае отказа от NAS разгружаем сеть,
* получаем большую скорость ввода-вывода за счет оптимизации на стороне системы хранения,
* получаем возможность подключать несколько серверов к одному ресурсу, то нам дает следующих двух зайцев:
o на полную используем возможности VMWare — например VMotion (миграцию виртуальной машины между физическими) и иже с ними,
o можем строить отказоустойчивые кластеры и организовывать территориально распределенные сети.
Что это дает?
Помимо освоения бюджета оптимизации системы хранения данных, мы получаем, вдобавок к тому что я написал выше:
* увеличение производительности, балансировку нагрузки и высокую доступность систем хранения за счет нескольких путей доступа к массивам;
* экономию на дисках за счет оптимизации расположения информации;
* ускоренное восстановление после сбоев — можно создать временные ресурсы, развернуть на них backup и подключить к ним сервера, а самим без спешки восстанавливать информацию, или перекинуть ресурсы на другие сервера и спокойно разбираться с умершим железом;
* уменьшение время резервного копирования — благодаря высокой скорости передачи можно бэкапиться на ленточную библиотеку быстрее, или вообще сделать snapshot (мгновенный снимок) с файловой системы и спокойно архивировать его;
* дисковое место по требованию — когда нам нужно — всегда можно добавить пару полок в систему хранения данных.
* уменьшаем стоимость хранения мегабайта информации — естественно, есть определенный порог, с которого эти системы рентабельны.
* надежное место для хранения mission critical и business critical данных (без которых организация не может существовать и нормально работать).
* отдельно хочу упомянуть VMWare — полностью все фишки вроде миграции виртуальных машин с сервера на сервер и прочих вкусностей доступны только на SAN.
Из чего это состоит?
Как я писал выше — СХД состоит из устройств хранения, среды передачи и подключенных серверов. Рассмотрим по порядку:
Системы хранения данных обычно состоят из жестких дисков и контроллеров, в уважающей себя системе как правило всего по 2 — по 2 контроллера, по 2 пути к каждому диску, по 2 интерфейса, по 2 блока питания, по 2 администратора. Из наиболее уважаемых производителей систем следует упомянуть HP, IBM, EMC и Hitachi. Тут процитирую одного представителя EMC на семинаре — «Компания HP делает отличные принтеры. Вот пусть она их и делает!» Подозреваю, что в HP тоже очень любят EMC. Конкуренция между производителями нешуточная, впрочем, как и везде. Последствия конкуренции — иногда вменяемые цены за мегабайт системы хранения и проблемы с совместимостью и поддержкой стандартов конкурентов, особенно у старого оборудования.
Среда передачи данных. Обычно SAN строят на оптике, это дает на текущий момент скорость в 4, местами в 8 гигабит на канал. При построении раньше использовались специализированные хабы, сейчас больше свитчи, в основном от Qlogic, Brocade, McData и Cisco (последние два на площадках не видел ни разу). Кабели используются традиционные для оптических сетей — одномодовые и многомодовые, одномодовые более дальнобойные.
Внутри используется FCP — Fibre Channel Protocol, транспортный протокол. Как правило внутри него бегает классический SCSI, а FCP обеспечивает адресацию и доставку. Есть вариант с подключением по обычной сети и iSCSI, но он обычно использует (и сильно грузит) локальную, а не выделенную под передачу данных сеть, и требует адаптеров с поддержкой iSCSI, ну и скорость помедленнее, чем по оптике.
Есть еще умное слово топология, которое встречается во всех учебниках по SAN. Топологий несколько, простейший вариант — точка-точка (point to point), соединяем между собой 2 системы. Это не DAS, а сферический конь в вакууме простейший вариант SAN. Дальше идет управляемая петля (FC-AL), она работает по принципу «передай дальше» — передатчик каждого устройства соединен с приемником последующего, устройства замкнуты в кольцо. Длинные цепочки имеют свойство долго инициализироваться.
Ну и заключительный вариант — коммутируемая структура (Fabric), она создается с помощью свитчей. Структура подключений строится в зависимости от количества подключаемых портов, как и при построении локальной сети. Основной принцип построения — все пути и связи дублируются. Это значит, что до каждого устройства в сети есть минимум 2 разных пути. Здесь тоже употребимо слово топология, в смысле организации схемы подключений устройств и соединения свитчей. При этом как правило свитчи настраиваются так, что сервера не видят ничего, кроме предназначенных им ресурсов. Это достигается за счет создания виртуальных сетей и называется зонированием, ближайшая аналогия — VLAN. Каждому устройству в сети присваивается аналог MAC-адреса в сети Ethernet, он называется WWN — World Wide Name. Он присваивается каждому интерфейсу и каждому ресурсу (LUN) систем хранения данных. Массивы и свитчи умеют разграничивать доступ по WWN для серверов.
Сервера подключают к СХД через HBA — Host Bus Adapter-ы. По аналогии с сетевыми картами существуют одно-, двух-, четырехпортовые адаптеры. Лучшие собаководы рекомендуют ставить по 2 адаптера на сервер, это позволяет как осуществлять балансировку нагрузки, так и обеспечивает надежность.
А дальше на системах хранения нарезаются ресурсы, они же диски (LUN) для каждого сервера и оставляется место в запас, все включается, установщики системы прописывают топологию, ловят глюки в настройке свитчей и доступа, все запускается и все живут долго и счастливо*.
Я специально не касаюсь разных типов портов в оптической сети, кому надо — тот и так знает или прочитает, кому не надо — только голову забивать. Но как обычно, при неверно установленном типе порта ничего работать не будет.
Из опыта.
Обычно при создании SAN заказывают массивы с несколькими типами дисков: FC для скоростных приложений, и SATA или SAS для не очень быстрых. Таким образом получаются 2 дисковые группы с различной стоимостью мегабайта — дорогая и быстрая, и медленная и печальная дешевая. На быструю вешаются обычно все базы данных и прочие приложения с активным и быстрым вводом-выводом, на медленную — файловые ресурсы и все остальное.
Если SAN создается с нуля — имеет смысл строить ее на основе решений от одного производителя. Дело в том, что, несмотря на заявленное соответствие стандартам, существуют подводные грабли проблемы совместимости оборудования, и не факт, что часть оборудования будет работать друг с другом без плясок с бубном и консультаций с производителями. Обычно для утряски таких проблем проще позвать интегратора и дать ему денег, чем общаться с переводящими друг на друга стрелки производителями.
Если SAN создается на базе существующей инфраструктуры — все может быть сложно, особенно если есть старые SCSI массивы и зоопарк старой техники от разных производителей. В этом случае имеет смысл звать на помощь страшного зверя интегратора, который будет распутывать проблемы совместимости и наживать третью виллу на Канарах.
Часто при создании СХД фирмы не заказывают поддержку системы производителем. Обычно это оправдано, если у фирмы есть штат грамотных компетентных админов (которые уже 100 раз назвали меня чайником) и изрядный капитал, позволяющий закупить запасные комплектующие в потребных количествах. Однако компетентных админов обычно переманивают интеграторы (сам видел), а денег на закупку не выделяют, и после сбоев начинается цирк с криками «Всех уволю!» вместо звонка в саппорт и приезда инженера с запасной деталью.
Поддержка обычно сводится к замене умерших дисков и контроллеров, ну и к добавлению в систему полок с дисками и новых серверов. Много хлопот бывает после внезапной профилактики системы силами местных специалистов, особенно после полного останова и разборки-сборки системы (и такое бывает).
Про VMWare. Насколько я знаю (спецы по виртуализации поправьте меня), только у VMWare и Hyper-V есть функционал, позволяющий «на лету» перекидывать виртуальные машины между физическими серверами. И для его реализации требуется, чтобы все сервера, между которыми перемещается виртуальная машина, были подсоединены к одному диску.
Про кластеры. Аналогично случаю с VMWare, известные мне системы построения отказоустойчивых кластеров (Sun Cluster, Veritas Cluster Server) — требуют подключенного ко всем системам хранилища.
Пока писал статью — у меня спросили — в какие RAIDы обычно объединяют диски?
В моей практике обычно делали или по RAID 1+0 на каждую дисковую полку с FC дисками, оставляя 1 запасной диск (Hot Spare) и нарезали из этого куска LUN-ы под задачи, или делали RAID5 из медленных дисков, опять же оставляя 1 диск на замену. Но тут вопрос сложный, и обычно способ организации дисков в массиве выбирается под каждую ситуацию и обосновывается. Та же EMC например идет еще дальше, и у них есть дополнительная настройка массива под приложения, работающие с ним (например под OLTP, OLAP). С остальными вендорами я так глубоко не копал, но догадываюсь, что тонкая настройка есть у каждого.
* до первого серьезного сбоя, после него обычно покупается поддержка у производителя или поставщика системы.
Поскольку в песочнице комментариев нет, закину в личный блог.
Источник