Что такое база данных на основе пар «ключ‑значение»?
База данных на основе пар «ключ‑значение» – это тип нереляционных баз данных, в котором для хранения данных используется простой метод «ключ‑значение». База данных на основе пар «ключ‑значение» хранит данные как совокупность пар «ключ‑значение», в которых ключ служит уникальным идентификатором. Как ключи, так и значения могут представлять собой что угодно: от простых до сложных составных объектов. Базы данных с использованием пар «ключ‑значение» поддерживают высокую разделяемость и обеспечивают беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов баз данных. Например, Amazon DynamoDB выделяет дополнительные разделы на таблицу, если существующий раздел заполняется до предела и требуется больше пространства для хранения.
На следующей диаграмме показан пример данных, хранящихся в виде пар «ключ‑значение» в DynamoDB.
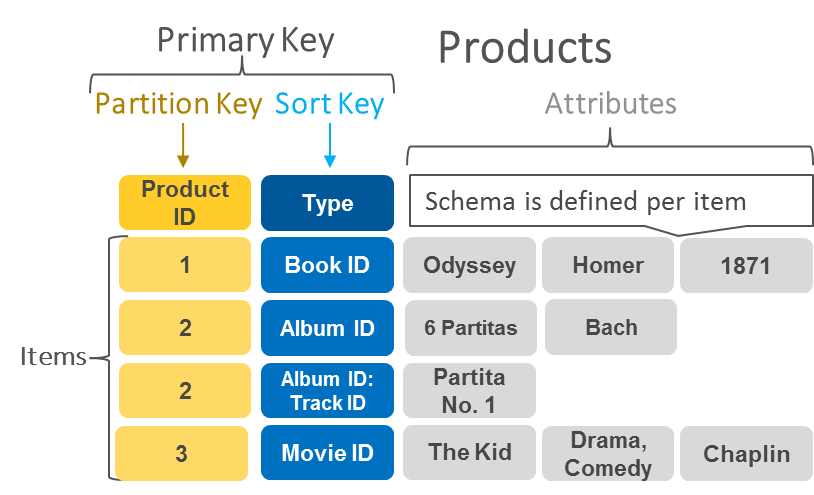
Примеры использования
Хранилище сессий
Основанное на сессиях приложение (например, интернет‑приложение) запускает сессию, когда пользователь входит в систему. Оно активно до тех пор, пока пользователь не выйдет из системы или не истечет время сессии. В течение этого периода приложение хранит все связанные с сессией данные либо в основной памяти, либо в базе данных. Данные сессии могут включать информацию профиля пользователя, сообщения, индивидуальные данные и темы, рекомендации, таргетированные рекламные кампании и скидки. Каждая сессия пользователя имеет уникальный идентификатор. Данные сессий всегда запрашиваются только по первичному ключу, поэтому для их хранения отлично подходит быстрое хранилище пар «ключ‑значение». В целом базы данных на основе пар «ключ‑значение» могут снижать накладные расходы в расчете на страницу по сравнению с реляционными базами данных.
Корзина интернет‑магазина
Во время праздничного сезона покупок сайт интернет‑магазина может получать миллиарды заказов за считаные секунды. Используя базы данных на основе пар «ключ‑значение», можно обеспечить необходимое масштабирование при существенном увеличении объемов данных и чрезвычайно интенсивных изменениях состояния. Такие базы данных позволяют одновременно обслуживать миллионы пользователей благодаря распределенным обработке и хранению данных. Базы данных на основе пар «ключ‑значение» также обладают встроенной избыточностью, что позволяет справляться с потерей узлов хранилища.
Популярные базы данных на основе пар «ключ‑значение»
Amazon DynamoDB
Amazon DynamoDB – это нереляционная база данных, обеспечивающая надежную производительность при любом масштабе. База данных является полностью управляемой и работает в нескольких регионах с несколькими ведущими серверами. Она обеспечивает устойчивую задержку в пределах нескольких миллисекунд и обладает встроенными средствами безопасности, резервного копирования и восстановления, а также кэширования в памяти. В DynamoDB элемент состоит из первичного или сложного ключа и переменного количества атрибутов. Явно заданных ограничений по количеству атрибутов, связанных с отдельным элементом, не существует, однако суммарный размер элемента, включая все имена и значения атрибутов, не должен превышать 400 КБ. Таблица представляет собой совокупность элементов данных, подобную совокупности строк в таблице реляционной базы данных. Каждая таблица может содержать бесконечное количество элементов данных.
С помощью этого пошагового учебного пособия можно настроить и запустить базу данных DynamoDB всего за 10 минут. Узнайте больше о DynamoDB и начните работу уже сегодня.
Источник
Использование key-value базы данных Snappy в Android
SnappyDB — NoSQL key-value база данных для Android. Она довольно проста в использовании и является неплохим вариантом, если вы хотите использовать NoSQL вариант базы данных в своём проекте (подробнее тут).
По заявлениям разработчиков, в операциях записи и чтения Snappy превосходит по скорости SQLite:

Итак, начнём. Для начала необходимо добавить dependencies в build.gradle:
implementation ‘com.snappydb:snappydb-lib:0.5.2’
implementation ‘com.esotericsoftware.kryo:kryo:2.24.0’
Теперь начнём, непосредственно, работу с самой БД.
Для начала разберёмся, как при помощи SnappyDB работать с примитивными типами и массивами, сохранять и получать их.
Для наглядности создадим небольшую разметку:
Допустим, что мы будем хранить в нашей БД данные о фильме
В MainActivity создадим метод PutValues:
Заметьте, что метод, в котором мы работаем со SnappyDB должен выбрасывать исключение SnappydbException.
Теперь напишем метод setValues для получения данных из БД и их вывода:
Вызовем созданные методы в onCreate (обязательно окружив их блоком try/catch):
Запускаем и видим, что всё работает исправно: 
А теперь разберёмся, как работать с собственными классами и другими сложными типами.
Создадим класс Film с 3 полями:
Уберём вызовы методов setValues и putValues в onCreate. Создадим в нём новый объект класса Film и добавим его в БД:
Переработаем метод setValues:
Вновь вызовем setValues в onCreate:
Запускаем и видим, что всё работает: 
Теперь давайте рассмотрим ещё несколько интересных функций SnappyDB:
1) Возможность искать ключи по префиксу:

Вывод в лог
2) Итерация по БД:
Без использования byBatch у вас будет только KeyIterator, который не реализует Iterator или Iterable, поэтому вы не можете использовать его в цикле.
byBatch (n) создает BatchIterable, который является Iterable и Iterator. По сути, он просто вызывает next (n) для KeyIterator, когда вы вызываете next () для него.
Но byBatch стоит использовать только при большом кол-ве данных. В ином случае стоит использовать findKeys/findKeysBetween.
3) Удаление элемента по ключу:

Элемент удалён
4) Закрытие и удаление БД:
5) Узнать, существует ли ключ в БД:
Ну вот и всё. Вам решать, использовать ли эту БД в своих проектах. Она достаточно быстра и проста в использовании, но выбор за вами. Это далеко не единственная БД для Android. Возможно, для вашего проекта лучше подойдёт другая БД (Room, SQLite, Realm и т.д). Вариантов масса.
Источник
TiKV — распределённая база данных key-value для cloud native

28 августа организация CNCF (Cloud Native Computing Foundation), стоящая за Kubernetes, Prometheus и другими Open Source-проектами для современных облачных приложений, объявила о принятии нового продукта в свою «песочницу» — TiKV.
Эта распределённая, транзакционная база данных типа ключ-значение зародилась как дополнение к TiDB — распределённой СУБД, которая предлагает возможности OLTP и OLAP и обеспечивает совместимость с протоколом MySQL… Но давайте обо всём по порядку.
TiDB как родитель
Начнём с «родительского» проекта TiDB, созданного китайской компанией PingCAP Inc.

Первый крупный публичный релиз этой СУБД — 1.0 — состоялся меньше года назад. Главные её особенности — «гибридность», совмещающая транзакционную и аналитическую обработку данных (Hybrid Transactional/Analytical Processing, HTAP), а также уже упомянутая совместимость с протоколом MySQL. Более полная картина TiDB возникает при упоминании других — уже обыденных для новых СУБД — фич, таких как горизонтальная масштабируемость, высокая доступность и строгое соответствие ACID.
Общая архитектура TiDB представляется следующим образом:
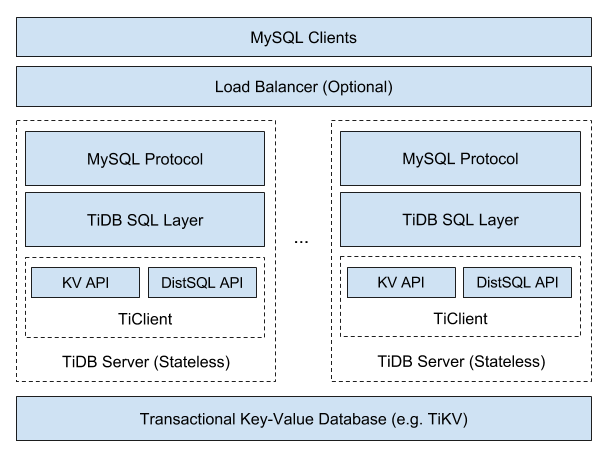
Поскольку TiDB предлагает масштабируемость NoSQL и гарантии по ACID, её относят к категории NewSQL. Авторы не скрывают, что создавали продукт под вдохновением от других представителей NewSQL: Google Spanner и F1. Однако китайские разработчики настаивали на «своих лучших практиках и решениях при выборе технологий». В частности, они выбрали алгоритм для решения задач консенсуса Raft (вместо Paxos, что используется в Spanner), хранилище RocksDB (вместо распределённой файловой системы), а в качестве языка программирования — Go (и Rust).
Многие подробности об устройстве TiDB можно найти в докладе «How we build TiDB» от соучредителя и генерального директора PingCAP — Max Liu, — а к некоторым из них, тесно связанным с TiKV, мы ещё вернёмся. Исходный код TiDB распространяется под свободной лицензией Apache License v2. Среди её крупных пользователей упоминаются Lenovo, Meizu, Bank of Beijing, Industrial and Commercial Bank of China и др.
Что же такое TiKV и какую роль играет в мире TiDB (и не только)?
Архитектура и особенности TiKV
Вернёмся к общей архитектуре TiDB, в чуть ином её представлении:

Можно увидеть, что сама TiDB обеспечивает реализацию SQL и совместимость с MySQL*, а остальную работу поручает кластеру TiKV. Что же это за «остальная работа»? Вот более подробная схема:
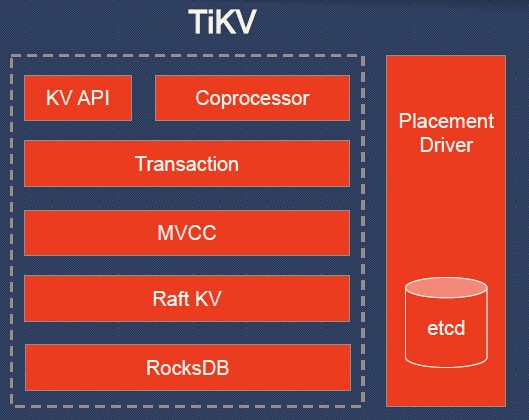
Преобразование таблиц в key-value происходит так, что из запросов:

Индексы в TiDB — обычные пары, значения в которых указывают на строку с данными:

Пояснения к схеме TiKV:
- KV API — набор программных интерфейсов для записи/чтения данных;
- Coprocessor — фреймворк сопроцессора для поддержки распределённых вычислений (сравнивается с аналогичным у HBase);
- Transaction — транзакционная модель, похожая на Google Percolator (протокол коммитов в 2 фазы; использует timestamp allocator; см. также сравнение со Spanner);
- MVCC (MultiVersion Concurrency Control) для обеспечения чтения без блокировок и ACID-транзакций (данные тегируются версиями; любые изменения, сделанные в текущей транзакции, не видны другим транзакциям до момента коммита);
- Raft KV — уже упомянутый алгоритм Raft, используемый для горизонтального масштабирования и консистентности данных; его реализация на языке Rust портирована из etcd (проверена обширной эксплуатацией); к слову, авторами TiKV заявлена «простая масштабируемость до 100+ Тб данных»;
- RocksDB — локальное хранилище типа ключ-значение, тоже уже хорошо зарекомендовавшее себя в масштабных проектах в production (Facebook);
- Placement Driver — «мозг» кластера, созданный по концепту из Google Spanner и отвечающий за хранение метаданных о регионах, поддержку нужного количества реплик, равномерное распределение нагрузок (с помощью Raft).

Если обобщить взаимосвязи основных компонентов, то получится следующее:
- У каждого узла кластера TiKV есть одно или несколько хранилищ (RocksDB).
- У каждого хранилища есть множество регионов.
- Регион является «базовой единицей движения данных key-value», реплицируется (с помощью Raft) на множество узлов. Такие наборы реплик образуют группы Raft.
- Наконец, управляющий этим кластером Placement Driver, как видно, и сам является кластером.
Установка и тестирование TiKV
Кодовая база TiKV написана преимущественно на Rust, но имеет и несколько сторонних компонентов на других языках (RocksDB на C++ и gRPC на Go). Распространяется под той же свободной лицензией Apache License v2.
Как уже говорилось в начале статьи, TiKV изначально появился как важная составляющая TiDB, но на сегодняшний день может эксплуатироваться как в рамках этой СУБД, так и отдельно. (Но в любом случае для её работы потребуется Placement Driver, написанный на Go и распространяемый как отдельный компонент).
Самая короткая инструкция для запуска TiKV вместе с СУБД TiDB требует наличия Git, Docker (17.03+), Docker Compose (1.6.0+), MySQL Client и сводится к следующей:
Результатом выполнения этих команд станет развёртывание кластера TiDB, по умолчанию состоящего из следующих компонентов:
- 1 экземпляр собственно TiDB;
- 3 экземпляра TiKV;
- 3 экземпляра Placement Driver;
- Prometheus и Grafana (для мониторинга и графиков);
- 2 экземпляра (мастер + слейв) TiSpark(прослойка для запуска Apache Spark поверх TiDB/TiKV для выполнения сложных OLAP-запросов);
- 1 экземпляр TiDB-Vision(для визуализации работы Placement Driver).
Дальнейшая работа с развёрнутой СУБД:
- подключение через MySQL-клиент: mysql -h 127.0.0.1 -P 4000 -u root ;
- веб-интерфейс Grafana для просмотра состояния кластера — http://localhost:3000 под admin/admin;
- веб-интерфейс TiDB-Vision для информации о балансировке нагрузки в кластере и миграции данных по узлам — http://localhost:8010 ;
- веб-интерфейс Spark — http://localhost:8080 (доступ к TiSpark — через spark://127.0.0.1:7077 ).
Если же хочется не совсем стандартного кластера TiDB (т.е. изменить его размеры, используемые Docker-образы, порты и т.п.), то после клонирования репозитория tidb-docker-compose можно отредактировать конфиг для Docker Compose:
Для ещё большей кастомизации — см. «Customize TiDB Cluster», где описана информация, откуда берутся конфиги для TiDB, TiKV, Placement Driver и другая специфика.
Для удобного деплоя TiDB в кластер Kubernetes подготовлен одноимённый оператор — TiDB Operator. Он есть в Helm-чартах, поэтому установка может быть сведена к следующим командам (слайд из презентации на TiDB DevConf 2018):

К слову, в той же презентации говорится о взгляде разработчиков TiDB на мониторинг этой СУБД. Текстовое описание, к сожалению, на китайском языке, но общее представление можно получить из этих слайдов:

Возвращаясь же к теме непосредственно TiKV — у этого проекты опубликованы свои руководства по запуску для тестовых целей:
Наконец, в качестве интерфейсов для работы с TiKV предлагаются:
Итоги
Зародившись как компонент более крупного Open Source-проекта китайской компании, TiKV уже успел завоевать известность в достаточно широких кругах. Статистика GitHub свидетельствует не только о 3600+ звёздах, но и почти 500 форках, и почти 100 контрибьюторах (хотя более 10 коммитов сделали лишь два десятка из них).
Присоединение TiKV к числу проектов CNCF и тот факт, что это первый проект подобного типа, тоже однозначно указывают на признание продукта сообществом cloud native… и должно придать импульс более активному развитию его кодовой базы сторонними (т.е. вне компании-основателя и её СУБД) специалистами.
Источник